Duration 30:00
Robots TXT File | Technical SEO | How To Create Robots.txt File on Website Complete Video in Urdu
Published 12 Apr 2023
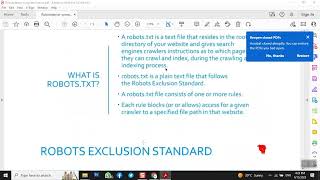
Robots TXT File | Technical SEO | How To Create Robots.txt File on Website Complete? Video in Urdu In the realm of website optimization and search engine crawling, the robots.txt file holds significant importance. This comprehensive guide aims to provide a thorough understanding of the robots.txt file, its purpose, and its role in controlling search engine crawlers. By grasping the concept and implementation of the robots.txt file, webmasters and SEO professionals can effectively manage the crawling and indexing process, ensuring their websites are optimized for search engines. 1.1 Introduction to Robots.txt: The robots.txt file is a plain text file located in the root directory of a website that provides instructions to search engine crawlers on which pages or directories to crawl and index and which ones to exclude. 1.2 Purpose of Robots.txt: The primary purpose of the robots.txt file is to guide search engine crawlers, also known as robots or spiders, on how to interact with a website, ensuring that desired content is indexed while preventing access to sensitive or irrelevant areas. Section 2: Interaction with Search Engine Crawlers (500-600 words) 2.1 Discovery of Robots.txt: Search engine crawlers discover the robots.txt file by accessing the root directory of a website and looking for a file named "robots.txt." 2.2 Crawl and Indexing Process: Search engine crawlers use the information provided in the robots.txt file to determine which pages and directories to crawl and index. It influences how search engines perceive and display a website in search results. 2.3 Importance of Robots.txt in Crawl Budget Optimization: An optimized robots.txt file can help improve crawl efficiency by guiding search engine crawlers to focus on the most valuable pages of a website, thus utilizing the crawl budget effectively. 3.1 User-agent Directive: The user-agent directive specifies the search engine crawler to which the subsequent directives apply, allowing website owners to provide instructions specific to different crawlers. 3.2 Disallow Directive: The disallow directive instructs search engine crawlers not to crawl and index specific pages or directories. It helps prevent unwanted pages or sections from appearing in search results. 3.3 Allow Directive: The allow directive allows search engine crawlers access to specific pages or directories, even if they are disallowed by default. It overrides any disallow directives that might prevent access. 3.4 Crawl-delay Directive: The crawl-delay directive specifies the delay between successive requests from search engine crawlers to manage server load and prevent excessive crawling. 3.5 Sitemap Directive: The sitemap directive informs search engine crawlers about the location of the XML sitemap file, which helps in comprehensive indexing and crawling. 4.1 Best Practices for Robots.txt Configuration: Guidelines for optimizing the robots.txt file include using relevant comments, maintaining a logical structure, and adhering to search engine-specific guidelines. 4.2 Handling Dynamic Content: Strategies for managing robots.txt directives for websites with dynamic or frequently changing content, ensuring that search engine crawlers access the most up-to-date information. 4.3 Testing and Validation: The importance of testing and validating the robots.txt file to ensure it functions as intended and doesn't unintentionally block or allow access to critical content. 5.1 Improved Indexing and Rankings: An optimized robots.txt file can positively impact search engine rankings by ensuring the crawling and indexing of valuable content, leading to improved visibility in search results. 5.2 Preventing Indexing of Duplicate Content: The robots.txt file helps prevent search engines from indexing
Category
Show more



Comments - 1
Related videos for Robots TXT File | Technical SEO | How To Create Robots.txt File on Website Complete Video in Urdu: